Normality tests

Tests of normality are statistical inference procedures designed to test that the underlying distribution of a random variable is normally distributed. There is a long history of these tests, and there are a plethora of them available for use, i.e. Jarque and Bera (1980), D’Agostino and Pearson (1973), Ralph B. D’agostino and Jr. (1990). Such kind of tests are based on the comparison of the sample skewness and kurtosis with the skewness and kurtosis of a normal distribution, hence their estimation is crucial.
1 Theoric Moments
1.1 Expectation
Let’s define and denote the expectation in population of a random variable
1.2 Variance
Let’s define and denote the population variance of a random variable
1.3 Skewness
Following the same notation as in Ralph B. D’agostino and Jr. (1990), let’s define and denote the population skewness of a random variable
Notably, in Urzúa (1996) are reported also the exact mean of the estimator in Equation 1 when
1.4 Kurtosis
Let’s define and denote the population kurtosis of a random variable
Notably in Urzúa (1996) are reported also the exact mean when
and the variance as:
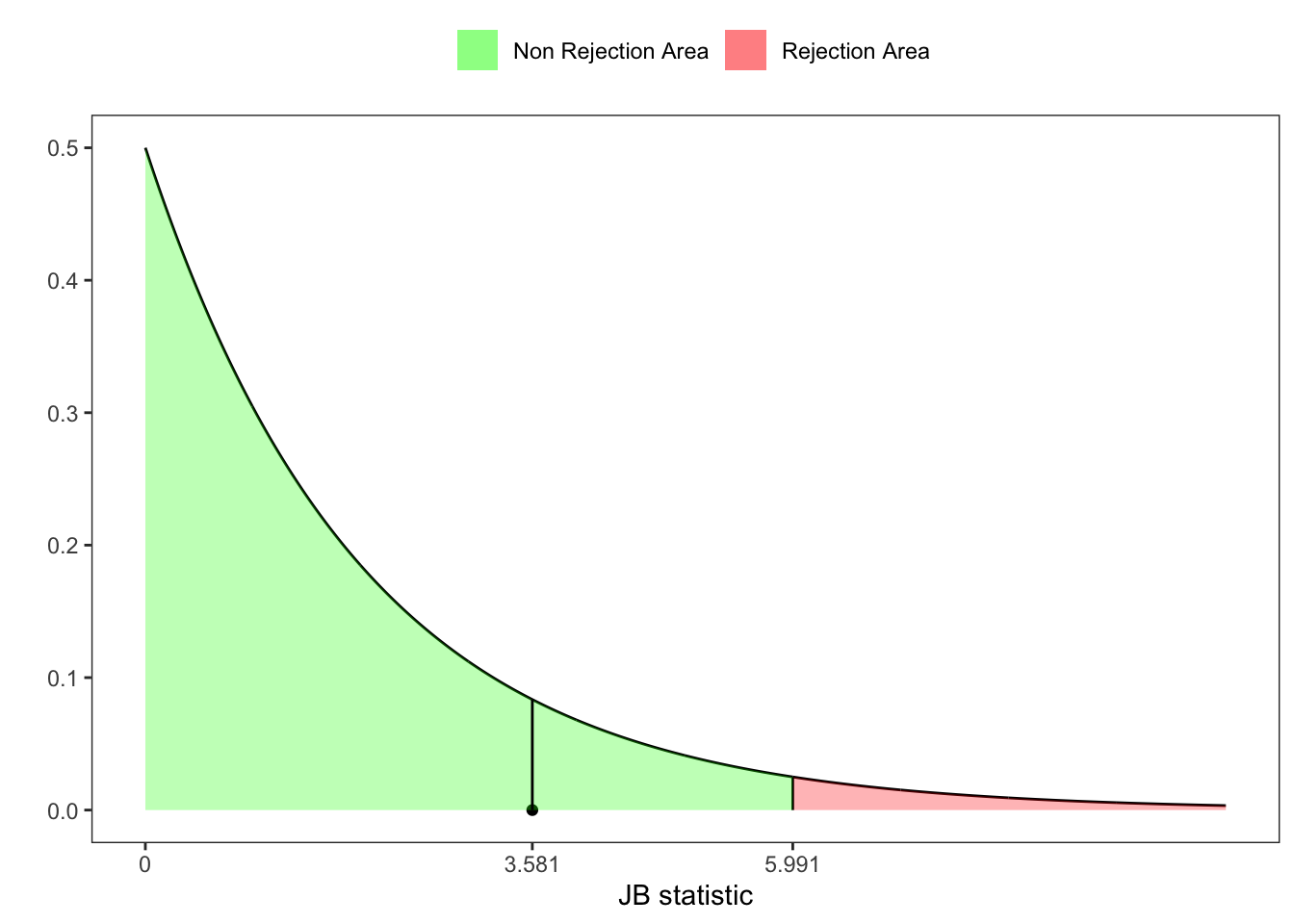
2 Jarque-Brera test
If
Jarque-Brera test
# =============== Setups ===============
n <- 50 # number of simulations
set.seed(1) # random seed
ci <- 0.05 # confidence level
# ======================================
# Simulated variable
x <- rnorm(n, 0, 1)
# Sample skewness
b1 <- skewness(x)
# Sample kurtosis
b2 <- kurtosis(x, excess = F)
# JB-statistic test
JB <- n*(b1^2/6 + (b2 - 3)^2/24)
# JB-test pvalue
pvalue <- 1 - pchisq(JB, df = 2)
# JB-test critic value at 95%
z_lim <- qchisq(1-ci, 2)
# =============== Plot ===============
# Grid of points
grid <- seq(0, 10, 0.01)
# Rejection area
grid_rej <- grid[grid > z_lim]
# Non-rejection area
grid_norej <- grid[grid < z_lim]
ggplot()+
geom_line(aes(grid, dchisq(grid, 2)))+
geom_segment(aes(z_lim, xend = z_lim, y = 0, yend = dchisq(z_lim, 2)))+
geom_point(aes(JB, 0))+
geom_ribbon(aes(x = grid_rej, ymin = 0, ymax = dchisq(grid_rej, 2), fill = "rej"), alpha = 0.3)+
geom_ribbon(aes(x = grid_norej, ymin = 0, ymax = dchisq(grid_norej, 2), fill = "norej"), alpha = 0.3)+
geom_segment(aes(JB, xend = JB, y = 0, yend = dchisq(JB, 2)))+
scale_x_continuous(breaks = c(0, JB, z_lim),
labels = c("0", format(c(JB, z_lim), digits = 4)))+
labs(x = "JB statistic", y = "", fill = NULL)+
scale_fill_manual(values = c(rej = "red", norej = "green"),
labels = c(rej = "Rejection Area", norej = "Non Rejection Area")) +
theme_bw()+
theme(
legend.position = "top",
panel.grid = element_blank()
)
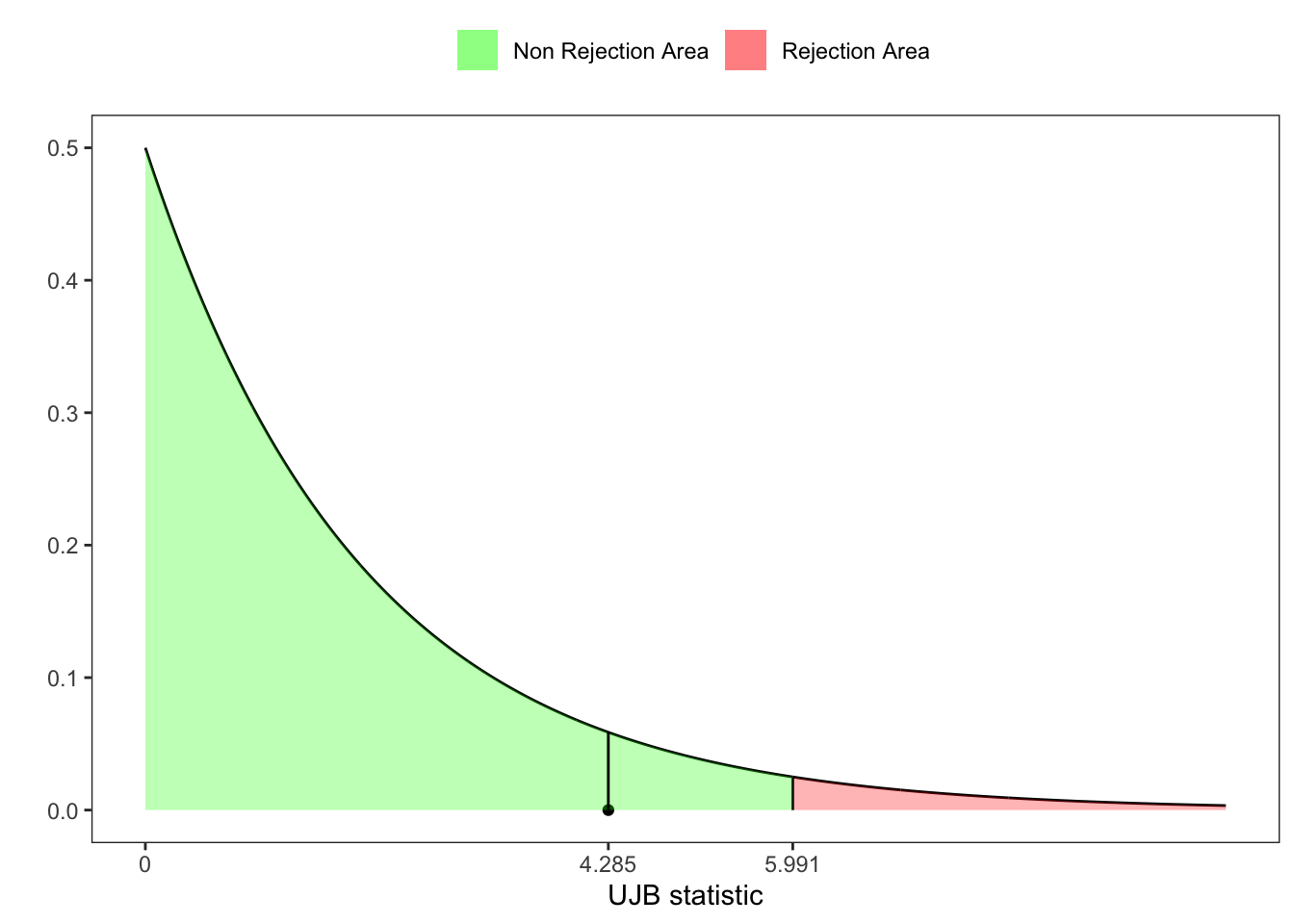
3 Urzua-Jarque-Brera test
Let’s substitute the asymptotic moments with the exact sample moments of skewness and kurtosis. Following Urzúa (1996), let’s write the new omibus test statistic as:
Urzua-Jarque-Brera test
# =============== Setups ===============
n <- 50 # number of simulations
set.seed(1) # random seed
ci <- 0.05 # confidence level
# ======================================
# Simulated variable
x <- rnorm(n, 0, 1)
# Sample skewness
b1 <- skewness(x)
# Skewness's variance
v_b1 <- (6*(n-2))/((n+1)*(n+3))
# Statistic for skewness
Z1 <- b1/sqrt(v_b1)
# Sample kurtosis
b2 <- kurtosis(x, excess = F)
# Kurtosis's expected value
e_b2 <- (3*(n-1))/(n+1)
# Kurtosis's variance
v_b2 <- (24*n*(n-2)*(n-3))/((n+1)^2*(n+3)*(n+5))
# Statistic for kurtosis
Z2 <- (b2-e_b2)/sqrt(v_b2)
# UJB-statistic test
UJB <- Z1^2 + Z2^2
# UJB p-value
pvalue <- 1 - pchisq(UJB, df = 2)
# UJB critic value at 95%
z_lim <- qchisq(1-ci, 2)
# =============== Plot ===============
# Grid of points
grid <- seq(0, 10, 0.01)
# Rejection area
grid_rej <- grid[grid > z_lim]
# Non-rejection area
grid_norej <- grid[grid < z_lim]
ggplot()+
geom_line(aes(grid, dchisq(grid, 2)))+
geom_segment(aes(z_lim, xend = z_lim, y = 0, yend = dchisq(z_lim, 2)))+
geom_point(aes(UJB, 0))+
geom_ribbon(aes(x = grid_rej, ymin = 0, ymax = dchisq(grid_rej, 2), fill = "rej"), alpha = 0.3)+
geom_ribbon(aes(x = grid_norej, ymin = 0, ymax = dchisq(grid_norej, 2), fill = "norej"), alpha = 0.3)+
geom_segment(aes(UJB, xend = UJB, y = 0, yend = dchisq(UJB, 2)))+
scale_x_continuous(breaks = c(0, UJB, z_lim),
labels = c("0", format(c(UJB, z_lim), digits = 4)))+
labs(x = "UJB statistic", y = "", fill = NULL)+
scale_fill_manual(values = c(rej = "red", norej = "green"),
labels = c(rej = "Rejection Area", norej = "Non Rejection Area")) +
theme_bw()+
theme(
legend.position = "top",
panel.grid = element_blank()
)
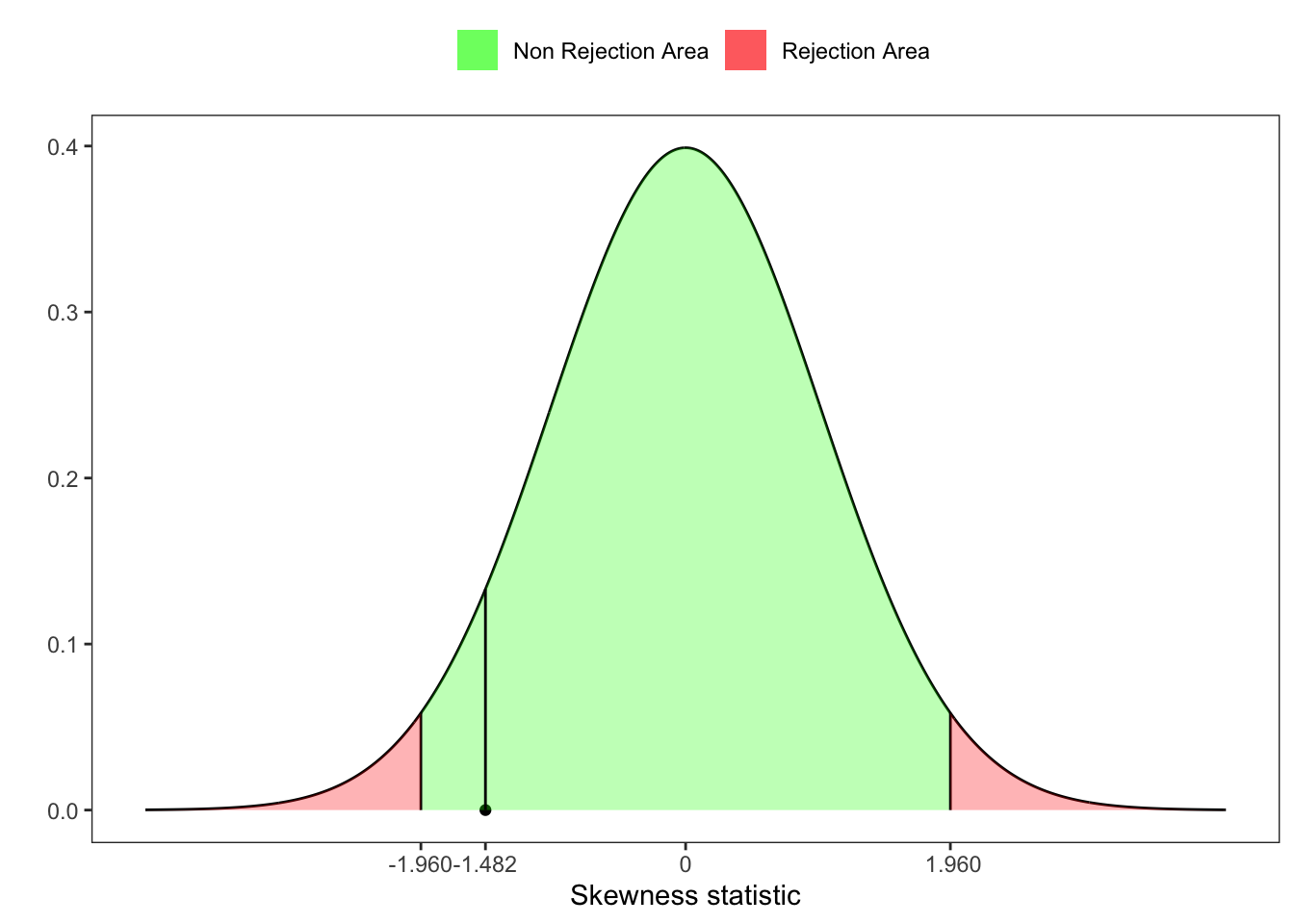
4 D’Agostino skewness test
D’Agostino and Pearson (1973) proposed an alternative way to test that the skewness is different from zero. Starting from the statistic
Skewness test
# =============== Setups ===============
n <- 20 # number of simulations
set.seed(1) # random seed
ci <- 0.05 # confidence level
# ======================================
# Simulated variable
x <- rnorm(n, 0, 1)
# Sample skewness
b1 <- skewness(x)
# Skewness's variance
v_b1 <- (6*(n-2))/((n+1)*(n+3))
# Statistic for skewness
Z1 <- b1/sqrt(v_b1)
# Test for Skewness
beta2_b1 <- (3*(n^2 + 27*n - 70)*(n+1)*(n+3))/((n-2)*(n+5)*(n+7)*(n+9))
W2 <- sqrt(2*beta2_b1 - 1) - 1
delta <- 1/sqrt(log(sqrt(W2)))
alpha <- sqrt(2/(W2 - 1))
# Test for skewness
Z_ast_b1 <- delta*asinh(Z1/alpha)
# UJB p-value
pvalue <- 1 - pnorm(Z_ast_b1, lower.tail = TRUE)
# UJB critic value at 95%
z_lim <- qnorm(1-ci/2)
# =============== Plot ===============
# Grid of points
grid <- seq(-4, 4, 0.01)
# Rejection area
grid_rej_l <- grid[grid >= z_lim]
grid_rej_r <- grid[grid <= -z_lim]
# Non-rejection area
grid_norej <- grid[!(grid > z_lim | grid < -z_lim)]
ggplot()+
geom_line(aes(grid, dnorm(grid)))+
geom_segment(aes(z_lim, xend = z_lim, y = 0, yend = dnorm(z_lim)))+
geom_segment(aes(-z_lim, xend = -z_lim, y = 0, yend = dnorm(-z_lim)))+
geom_point(aes(Z_ast_b1, 0))+
geom_ribbon(aes(x = grid_rej_l, ymin = 0, ymax = dnorm(grid_rej_l), fill = "rej"), alpha = 0.3)+
geom_ribbon(aes(x = grid_rej_r, ymin = 0, ymax = dnorm(grid_rej_r), fill = "rej"), alpha = 0.3)+
geom_ribbon(aes(x = grid_norej, ymin = 0, ymax = dnorm(grid_norej), fill = "norej"), alpha = 0.3)+
geom_segment(aes(Z_ast_b1, xend = Z_ast_b1, y = 0, yend = dnorm(Z_ast_b1)))+
scale_x_continuous(breaks = c(0, Z_ast_b1, z_lim, -z_lim),
labels = c("0", format(c(Z_ast_b1, z_lim, -z_lim), digits = 4)))+
labs(x = "Skewness statistic", y = "", fill = NULL)+
scale_fill_manual(values = c(rej = "red", norej = "green"),
labels = c(rej = "Rejection Area", norej = "Non Rejection Area")) +
theme_bw()+
theme(
legend.position = "top",
panel.grid = element_blank()
)
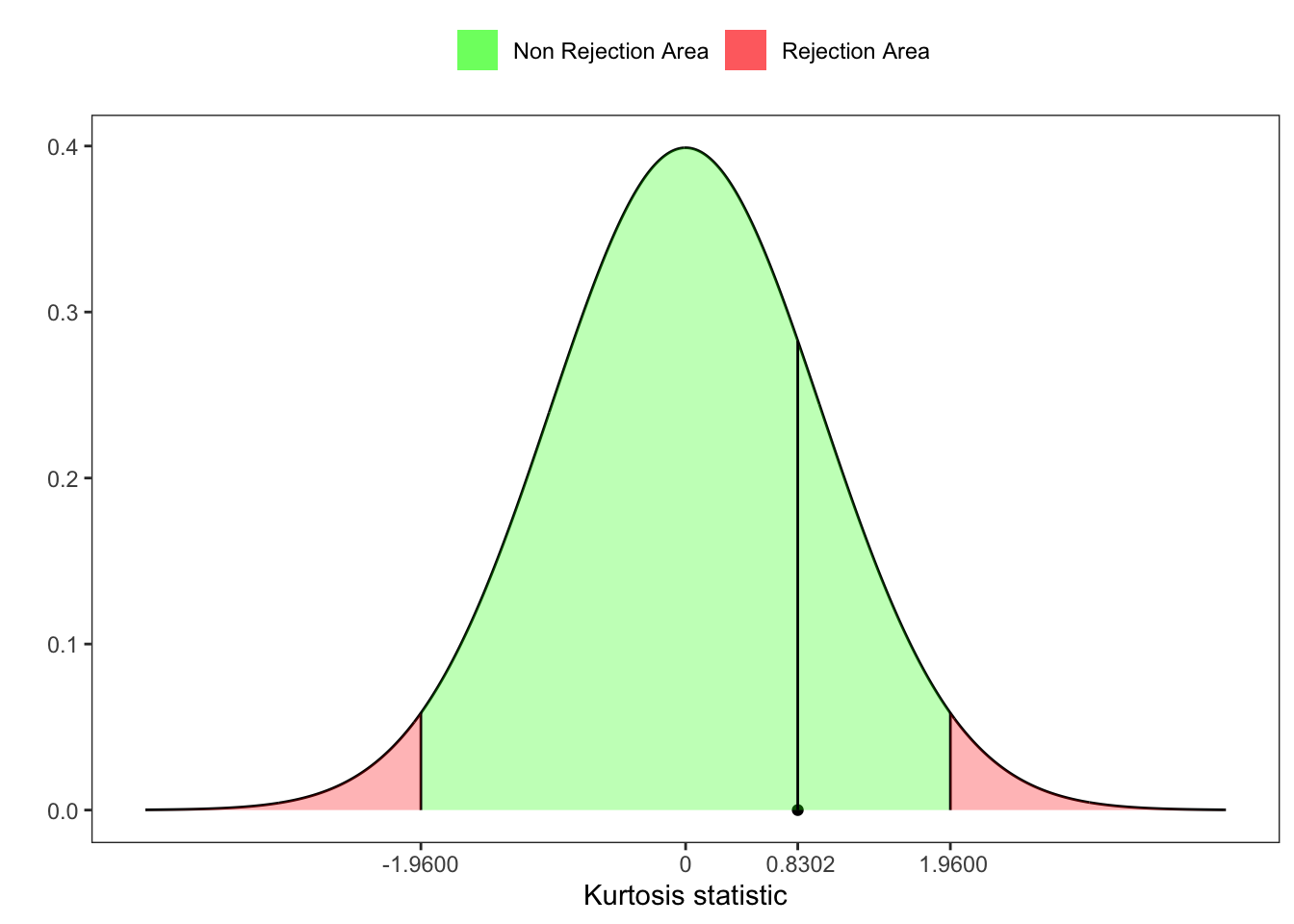
5 Anscombe Kurtosis test
Anscombe and Glynn (1983) proposed a test for skewness. Starting from the statistic
Urzua-Jarque-Brera test
# =============== Setups ===============
n <- 50 # number of simulations
set.seed(1) # random seed
ci <- 0.05 # confidence level
# ======================================
# Simulated variable
x <- rnorm(n, 0, 1)
# Sample kurtosis
b2 <- kurtosis(x, excess = F)
# Kurtosis's expected value
e_b2 <- (3*(n-1))/(n+1)
# Kurtosis's variance
v_b2 <- (24*n*(n-2)*(n-3))/((n+1)^2*(n+3)*(n+5))
# Statistic for kurtosis
Z2 <- (b2-e_b2)/sqrt(v_b2)
# Test for Skewness
beta1_b2 <- (6*(n^2 - 5*n + 2))/((n+7)*(n+9))*sqrt((6*(n+3)*(n+5))/(n*(n-2)*(n-3)))
A <- 6 + (8/beta1_b2)*(2/beta1_b2 + sqrt(1 + 4/(beta1_b2^2)))
# Test for kurtosis
Z_ast_b2 <- sqrt((9*A)/2) *(1 - 2/(9*A) - ((1 - 2/A)/(1 + Z2*sqrt(2/(A-4))))^(1/3))
# p-value
pvalue <- 1 - pnorm(Z_ast_b2, lower.tail = TRUE)
# UJB critic value at 95%
z_lim <- qnorm(1-ci/2)
# =============== Plot ===============
# Grid of points
grid <- seq(-4, 4, 0.01)
# Rejection area
grid_rej_l <- grid[grid >= z_lim]
grid_rej_r <- grid[grid <= -z_lim]
# Non-rejection area
grid_norej <- grid[!(grid > z_lim | grid < -z_lim)]
ggplot()+
geom_line(aes(grid, dnorm(grid)))+
geom_segment(aes(z_lim, xend = z_lim, y = 0, yend = dnorm(z_lim)))+
geom_segment(aes(-z_lim, xend = -z_lim, y = 0, yend = dnorm(-z_lim)))+
geom_point(aes(Z_ast_b2, 0))+
geom_ribbon(aes(x = grid_rej_l, ymin = 0, ymax = dnorm(grid_rej_l), fill = "rej"), alpha = 0.3)+
geom_ribbon(aes(x = grid_rej_r, ymin = 0, ymax = dnorm(grid_rej_r), fill = "rej"), alpha = 0.3)+
geom_ribbon(aes(x = grid_norej, ymin = 0, ymax = dnorm(grid_norej), fill = "norej"), alpha = 0.3)+
geom_segment(aes(Z_ast_b2, xend = Z_ast_b2, y = 0, yend = dnorm(Z_ast_b2)))+
scale_x_continuous(breaks = c(0, Z_ast_b2, z_lim, -z_lim),
labels = c("0", format(c(Z_ast_b2, z_lim, -z_lim), digits = 4)))+
labs(x = "Kurtosis statistic", y = "", fill = NULL)+
scale_fill_manual(values = c(rej = "red", norej = "green"),
labels = c(rej = "Rejection Area", norej = "Non Rejection Area")) +
theme_bw()+
theme(
legend.position = "top",
panel.grid = element_blank()
)
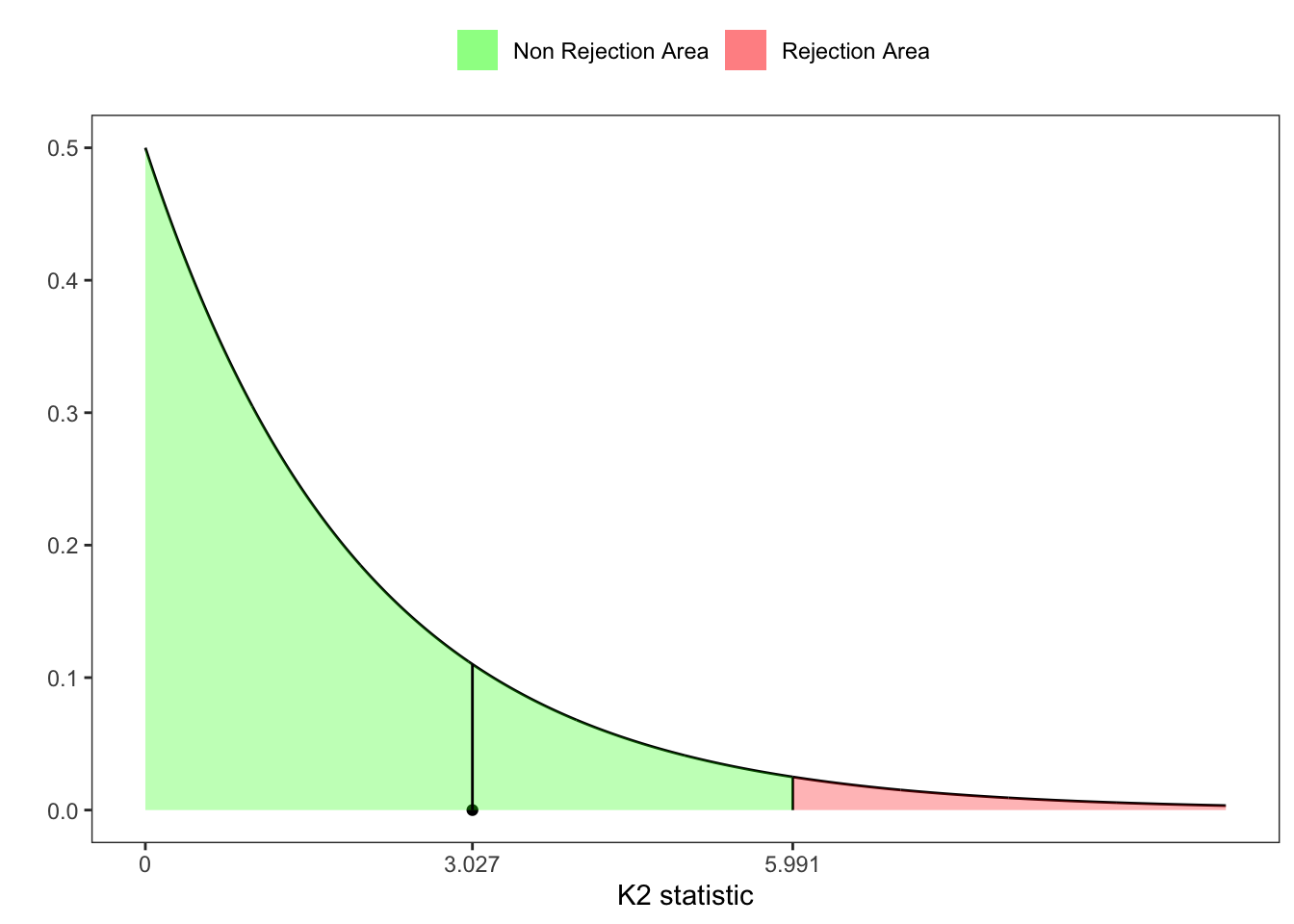
6 D’Agostino-Pearson
Finally in Ralph B. D’agostino and Jr. (1990), there is also another omibus test based on the statistics
Urzua-Jarque-Brera test
# K2-statistic test
K2 <- Z_ast_b1^2 + Z_ast_b2
# p-value
pvalue <- 1 - pchisq(K2, df = 2)
# ritic value at 95%
z_lim <- qchisq(1-ci, 2)
# =============== Plot ===============
# Grid of points
grid <- seq(0, 10, 0.01)
# Rejection area
grid_rej <- grid[grid > z_lim]
# Non-rejection area
grid_norej <- grid[grid < z_lim]
ggplot()+
geom_line(aes(grid, dchisq(grid, 2)))+
geom_segment(aes(z_lim, xend = z_lim, y = 0, yend = dchisq(z_lim, 2)))+
geom_point(aes(K2, 0))+
geom_ribbon(aes(x = grid_rej, ymin = 0, ymax = dchisq(grid_rej, 2), fill = "rej"), alpha = 0.3)+
geom_ribbon(aes(x = grid_norej, ymin = 0, ymax = dchisq(grid_norej, 2), fill = "norej"), alpha = 0.3)+
geom_segment(aes(K2, xend = K2, y = 0, yend = dchisq(K2, 2)))+
scale_x_continuous(breaks = c(0, K2, z_lim),
labels = c("0", format(c(K2, z_lim), digits = 4)))+
labs(x = "K2 statistic", y = "", fill = NULL)+
scale_fill_manual(values = c(rej = "red", norej = "green"),
labels = c(rej = "Rejection Area", norej = "Non Rejection Area")) +
theme_bw()+
theme(
legend.position = "top",
panel.grid = element_blank()
)
7 Kolmogorov-Smirnov Test
The Kolmogorov–Smirnov test can be used to verify whether a samples is drawn from a reference distribution. In the case of q sample with dimension
Kolmogorov distribution
# Infinite sum function
# k: approximation for infinity
inf_sum <- function(x, k = 100){
isum <- 0
for(i in 1:k){
isum <- isum + 2*(-1)^(i-1)*exp(-2*(x^2)*(i^2))
}
isum
}
# Kolmogorov distribution function
pks <- function(x, k = 100){
p <- c()
for(i in 1:length(x)){
p[i] <- 1-inf_sum(x[i], k = k)
}
p
}
# Kolmogorov quantile function
qks <- function(p, k = 100){
loss <- function(x, p){
(pks(x, k = k) - p)^2
}
x <- c()
for(i in 1:length(p)){
x[i] <- optim(par = 2, method = "Brent", lower = 0, upper = 10, fn = loss, p = p[i])$par
}
x
}The null distribution of this statistic is calculated under the null hypothesis that the sample is drawn from the reference distribution
7.1 Example 1: KS test for normality
Let’s simulate 500 observations of a stationary normal random variable, i.e.
Kolmogorov test (normal)
# ================== Setups ==================
set.seed(1) # random seed
n <- 5000 # number of simulations
k <- 1000 # index for Kolmogorov cdf approx
ci <- 0.05 # confidence level (alpha)
# ===========================================
# Simulated stationary sample
x <- rnorm(n, 0.2, 1)
# Set the interval values for upper and lower band
grid <- seq(quantile(x, 0.015), quantile(x, 0.985), 0.01)
# Empirical cdf
cdf <- ecdf(x)
# Compute the KS-statistic
ks_stat <- sqrt(n)*max(abs(cdf(grid) - pnorm(grid, mean = 0.2)))
# Compute the rejection level
rejection_lev <- qks(1-ci, k = k)
# ================== Kable ==================
kab <- dplyr::tibble(
n = n,
alpha = paste0(format(ci*100, digits = 3), "%"),
KS = ks_stat,
rejection_lev = rejection_lev,
H0 = ifelse(KS > rejection_lev, "Rejected", "Non-Rejected")
) %>%
dplyr::mutate_if(is.numeric, format, digits = 4, scientific = FALSE)
colnames(kab) <- c("$$n$$","$$\\alpha$$","$$KS_{n}$$",
"$$\\textbf{Critical Level}$$","$$H_0$$")
knitr::kable(kab, booktabs = TRUE ,escape = FALSE, align = 'c')%>%
kableExtra::row_spec(0, color = "white", background = "green") - 1
- Simulated stationary sample
- 2
- Set the interval values for upper and lower band. This is done to avoid including outliers, however it is possible to use also the minimum and maximum.
- 3
- Empirical cdf
- 4
- Compute the KS-statistic as in Equation 8.
- 5
- Compute the rejection level
7.2 Example 2: KS test for normality
Let’s simulate 500 observations of a stationary t-student random variable with increasing degrees of freedom
Kolmogorov test (normal vs student-t)
# ================== Setups ==================
seed <- 1 # random seed
n <- 5000 # number of simulations
k <- 1000 # index for Kolmogorov cdf approx
ci <- 0.05 # confidence level (alpha)
# grid for student-t degrees of freedom
nu <- c(1,5,10,15,20,30)
# ===========================================
kabs <- list()
for(v in nu){
set.seed(seed)
# Simulated stationary sample
x <- rt(n, df = v)
# Set the interval values for upper and lower band
grid <- seq(quantile(x, 0.015), quantile(x, 0.985), 0.01)
# Empirical cdf
cdf <- ecdf(x)
# Compute the KS-statistic
ks_stat <- sqrt(n)*max(abs(cdf(grid) - pnorm(grid, mean = 0, sd = 1)))
# Compute the rejection level
rejection_lev <- qks(1-ci, k = k)
kabs[[v]] <- dplyr::tibble(nu = v,
n = n,
alpha = paste0(format(ci*100, digits = 3), "%"),
KS = ks_stat,
rej_lev = rejection_lev,
H0 = ifelse(KS > rej_lev, "Rejected", "Non-Rejected")
)
}
# =============== Kable ===============
kab <- dplyr::bind_rows(kabs) %>%
dplyr::mutate_if(is.numeric, format, digits = 4, scientific = FALSE)
colnames(kab) <- c("$$\\nu$$", "$$n$$", "$$\\alpha$$", "$$KS_{n}$$",
"$$\\textbf{Critical Level}$$", "$$H_0$$")
knitr::kable(kab, booktabs = TRUE ,escape = FALSE, align = 'c')%>%
kableExtra::row_spec(0, color = "white", background = "green") References
Citation
@online{sartini2024,
author = {Sartini, Beniamino},
title = {Normality Tests},
date = {2024-05-01},
url = {https://greenfin.it/statistics/tests/normality-tests.html},
langid = {en}
}